筛斗数据平台科技闪耀登场2025服贸会 十团网络公司作为数据服务领域优势企业参展,以《筛斗数据要素清洗解决方案》为代表产品开启本届服务贸易新篇章! 数据清洗 2025年09月17日 1 点赞 0 评论 538 浏览
筛斗数据平台应用场景:文件解析管理--多格式识别,非结构化数据秒处理 筛斗数据平台的核心优势,在于将人工智能技术与文件解析管理深度融合,全面突破了传统处理模式的束缚。 数据清洗 2025年11月21日 2 点赞 0 评论 470 浏览
你的数据正在“裸奔”:那层最危险的漏洞,可能正藏在一次寻常的转发里 一家中型企业的CEO最近常被同一个噩梦惊醒:公司并未遭遇黑客攻击,却因内部一份流转了三年的客户数据表格,收到了监管部门的巨额罚单。调查发现,这份包含完整个人信息的数据,最初只是市场部向技术部门索要的“样本”,却在无数次的邮件转发、下载存储中彻底失控。 数据清洗 2025年12月05日 1 点赞 0 评论 461 浏览
数据清洗:仲裁行业数字化转型的“证据基石”与“效率引擎” 仲裁作为多元化纠纷解决机制的核心组成,其业务全流程高度依赖数据支撑 —— 从当事人信息、证据材料、案件审理记录到裁决文书,每一环都产生海量数据。但传统仲裁数据管理中,普遍存在三大核心痛点,让数据清洗成为数字化转型的 “必选项”: 数据清洗 2025年11月29日 1 点赞 0 评论 457 浏览
当我们谈论数据清洗,我们到底在谈论什么? 数据清洗的本质,是让数据从“原始素材”转化为“可用资产”的过程。它存在三重递进的境界,绝大多数企业只停留在第一重。 数据清洗 2025年12月04日 1 点赞 0 评论 451 浏览
大数据不只是 “海量数据”,更是驱动时代的创新引擎 大数据的价值,早已超越技术本身,深度融入各行各业的核心场景,成为产业升级的 “隐形引擎”。 数据治理 2025年11月22日 3 点赞 0 评论 381 浏览
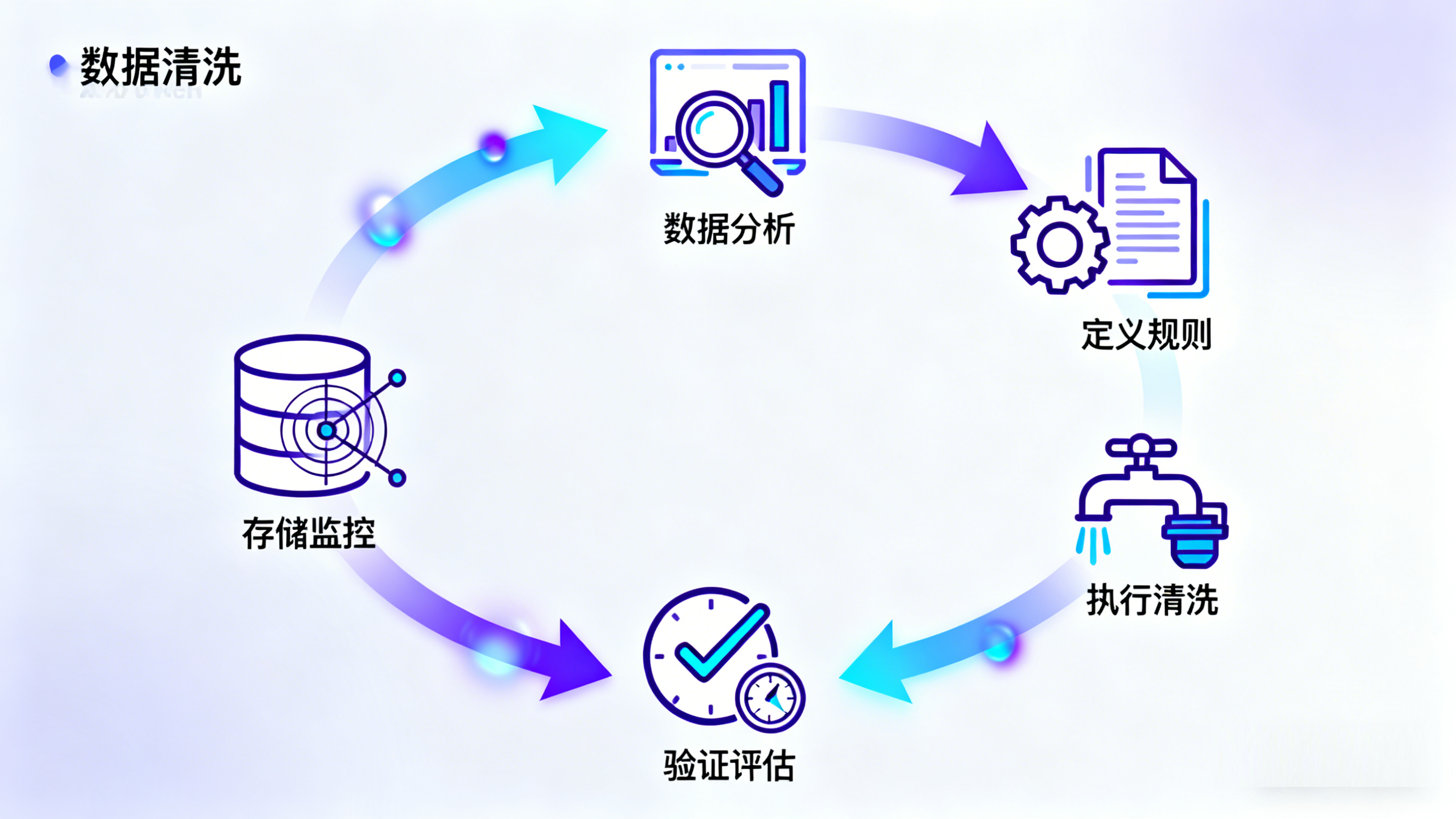
数据清洗:从“脏数据”到“干净数据”的蜕变之旅 在数据爆炸的时代,数据已成为企业决策、科学研究和日常运营的重要资产。然而,原始数据往往充斥着错误、缺失、不一致和噪声,这些“脏数据”如果直接用于分析和建模,会导致结果偏差,影响决策的有效性。因此,数据清洗作为数据处理的第一步,显得尤为重要。本文将深入探讨数据清洗的内容和方法,帮助读者全面理解这一关键过程。 数据清洗 2025年11月28日 1 点赞 0 评论 369 浏览
AI撞上了看不见的天花板:当算力狂奔,数据却在原地踏步 硅谷的投资人还在为下一个万亿参数模型兴奋不已,北京的AI实验室里却在上演着另一番景象。一位资深数据科学家指着屏幕上跳动的训练曲线,对团队说:“我们不是在教AI学习,是在教它模仿我们的混乱。”他们的模型准确率卡在82%已经三周了——不是因为算法不够精妙,而是训练数据里那些自相矛盾的标签,让AI陷入了困惑。 数据清洗 2025年12月06日 0 点赞 0 评论 367 浏览
数据清洗:企业数字化转型的“基石工程” 在数字化浪潮下,数据已成为企业决策的 “核心资产”。但现实中,企业收集的数据往往存在 “脏数据” 问题:客户信息重复录入、订单日期格式混乱、数值字段存在异常值、空白数据遗漏填充…… 这些看似微小的瑕疵,却可能导致市场分析失真、决策判断失误、业务流程受阻。 数据清洗 2025年12月12日 1 点赞 0 评论 344 浏览
AI的“毒饲料”:揭秘大模型训练中不为人知的数据清洗 我们喂养AI的每一口数据,都可能暗藏毒素。当ChatGPT对答如流、Sora生成精美视频时,很少有人知道,这些能力建立在数百万小时的数据清洗劳动之上——而这个过程,充满不为人知的算法偏见和政治权衡。 数据清洗 2025年12月11日 1 点赞 0 评论 319 浏览