数据清洗:从“脏数据”到“干净数据”的蜕变之旅
在数据爆炸的时代,数据已成为企业决策、科学研究和日常运营的重要资产。然而,原始数据往往充斥着错误、缺失、不一致和噪声,这些“脏数据”如果直接用于分析和建模,会导致结果偏差,影响决策的有效性。因此,数据清洗作为数据处理的第一步,显得尤为重要。本文将深入探讨数据清洗的内容和方法,帮助读者全面理解这一关键过程。
在数据爆炸的时代,数据已成为企业决策、科学研究和日常运营的重要资产。然而,原始数据往往充斥着错误、缺失、不一致和噪声,这些“脏数据”如果直接用于分析和建模,会导致结果偏差,影响决策的有效性。因此,数据清洗作为数据处理的第一步,显得尤为重要。本文将深入探讨数据清洗的内容和方法,帮助读者全面理解这一关键过程。
数据清洗的定义与重要性
数据清洗,也称为数据净化或数据清理,是指对原始数据进行处理,以纠正或删除错误、不完整、重复或不相关的部分,从而提高数据的质量和可用性。它
是数据预处理的重要环节,为后续的数据分析、数据挖掘和决策支持提供可靠的基础。
数据清洗的重要性不言而喻。高质量的数据是数据分析和机器学习模型的基石。如果数据存在错误或不一致,分析结果将不可靠,模型性能也会受到影响。此外,数据清洗还能帮助企业降低运营风险,提高决策效率,优化资源配置。
一、数据清洗的主要内容
(一)缺失值处理

缺失值是数据集中常见的问题,可能由数据采集错误、传输丢失或人为疏忽等原因引起。处理缺失值的方法包括:
1.删除:直接删除含有缺失值的行或列。这种方法适用于缺失值较少且对整体数据分析影响不大的情况。
2.插值:根据其他样本的值估计缺失值。常用的插值方法包括均值插值、中位数插值、众数插值等。
3.使用默认值:为缺失值设定一个合理的默认值,如0、平均值或某个特定代码。
(二)重复值处理

重复值会增加数据量,影响分析效率和结果的准确性。处理重复值的方法有:
1.删除:删除所有重复的行,只保留唯一的数据记录。
2.保留首行/末行:在存在重复行的情况下,选择保留每组重复行的首行或末行数据,并删除其余行。
3.自定义:根据业务需求,定义自定义方法来处理重复项,如合并重复项中的某些字段。
(三)异常值处理
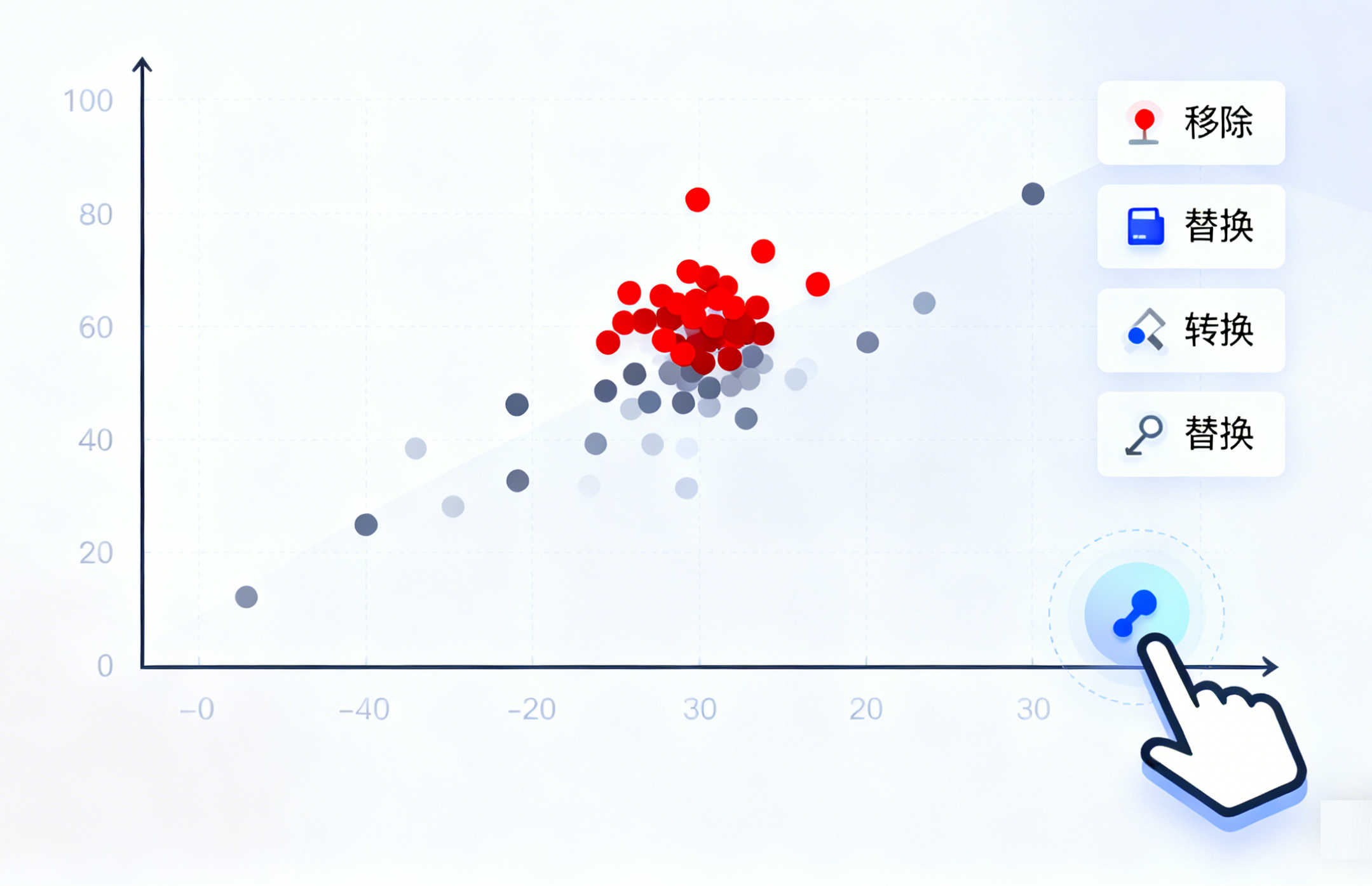
异常值是指明显偏离正常范围的数据点,可能由测量误差、数据录入错误或特殊情况引起。处理异常值的方法包括:
1.移除:直接删除异常数据点。
2.修剪:只保留指定百分比的数据,丢弃极端值。
3.替换:用更接近其他数据点的指定值替换异常值,如平均值、中位数等。
4.转换:通过数据转换(如对数转换)来减少异常值的影响。
(四)数据格式转换
数据格式不一致会增加数据处理的复杂性。数据格式转换的目标是将数据统一为一致的格式,以便于处理和分析。例如,将日期格式标准化为ISO格式,或将字符串转换为数字。
(五)数据标准化与归一化
数据标准化是将数据转换为统一的尺度,以便于比较和分析。常用的标准化方法包括Min-Max归一化和Z-Score归一化。
(六)数据去重与合并
数据去重是去除数据集中的重复记录,确保数据的唯一性。数据合并则是将来自多个来源的数据组合到单个统一视图中,以提供一致、准确的数据表示。
(七)数据一致性检查
数据一致性检查旨在发现并纠正数据中的不一致问题。例如,检查所有日期是否遵循相同的格式,或检查文本数据是否使用相同的字符编码。
(八)数据降维
数据降维是将高维数据降到低维,以减少数据量并提高分析效率。常用的降维方法包括主成分分析(PCA)、线性判别分析(LDA)等。
(九)数据离散化
数据离散化是将连续型数据转换为离散型数据,以便于某些特定的数据分析任务,如分类和聚类。
(十)数据平滑
数据平滑是对数据进行平滑处理,以减少噪声和异常值的影响,使数据更易于分析。常用的平滑方法包括移动平均法、指数平滑法等。
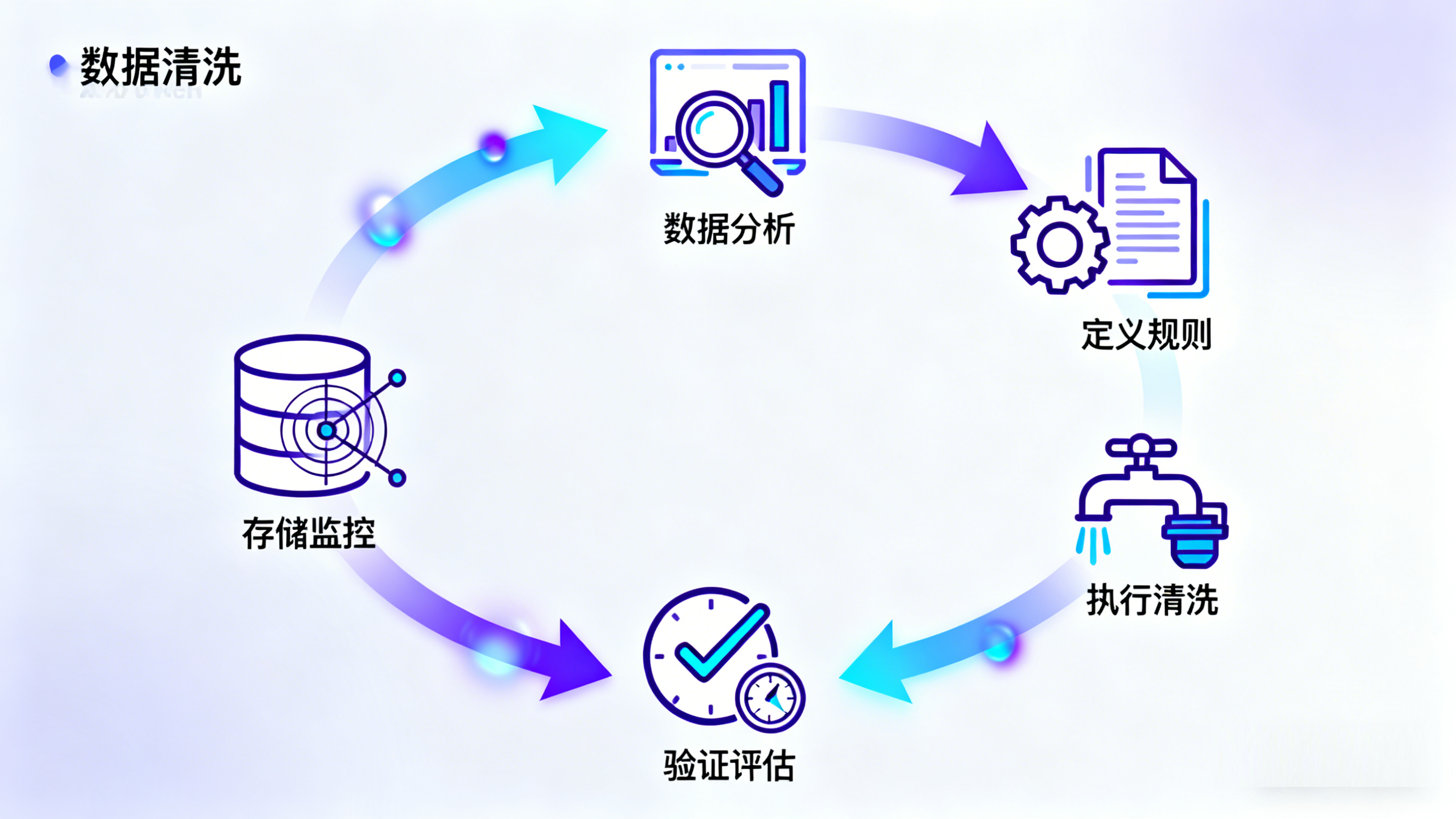
(二)数据清洗的流程
数据清洗的流程通常包括以下几个步骤:
数据分析:对数据进行初步分析,识别数据中的错误、不一致和缺失值。
定义清洗规则:根据分析结果,定义数据清洗的转换规则和策略。
执行清洗:应用清洗规则,对数据进行处理和修正。
验证与评估:验证清洗后的数据质量,评估清洗效果,并根据需要进行迭代优化。
存储与监控:将清洗后的数据存储到合适的位置,并持续监控数据质量,确保其长期稳定。
(三)数据清洗的工具与技术
随着数据量的不断增长,手动进行数据清洗已不现实。幸运的是,有许多工具和技术可以帮助我们高效地完成数据清洗任务。例如,Python中的Pandas和NumPy库提供了丰富的数据处理功能,Apache Spark则适用于大规模数据的分布式清洗。
结语
数据清洗是数据分析和机器学习的基础,它通过纠正错误、填补缺失和统一格式,为高质量的数据分析提供保障。在实际操作中,数据清洗需要结合业务需求和数据特点,选择合适的方法和工具。只有经过彻底清洗的“干净数据”,才能真正发挥其价值,为决策提供有力支持。