电商与零售
清洗商品库、订单库、会员库与活动数据,统一编码和标签体系,支撑精准营销与经营分析。
面向政企、金融、电商、制造、医疗等场景,提供重复数据去重、字段规范化、缺失修复、异常值治理等全链路服务,帮助企业大幅提升数据可用性与分析效率。
营销型站点不仅要展示服务,还要清晰表达客户痛点、解决路径与商业价值。这个页面围绕“转化 + SEO”设计,用结构化信息帮助搜索引擎理解,也让客户快速判断是否适合合作。
客户库、订单库、供应商库重复记录过多,导致销售触达冲突、分析失真与存储浪费。
手机号、地址、统一社会信用代码等关键字段缺失或异常,影响后续业务联动与风控判断。
同一字段存在多种录入方式,难以做聚合、对比、统计与自动化流转。
不准确的数据会带来决策偏差,也可能在审计、风控与客户服务环节形成隐患。
我们并非只做简单格式修正,而是结合业务规则、行业标准与目标系统要求,对数据进行清洗、校验、归一、映射与结构化交付。
去重、去空格、符号修正、乱码处理、非法字符过滤、日期与编码规范化。
基于企业业务规则校验字段逻辑、主外键关系、状态流转与必填一致性。
对票据、证照、合同、文本、图片资料做结构化抽取并对接清洗流程。
支持 Excel、CSV、数据库表、API 字段映射、标签体系与治理报告输出。
明确数据来源、字段结构、业务目标、质量问题与验收标准。
制定清洗规则、映射规则、去重逻辑和异常值处理策略。
先用样本数据验证规则效果,确保清洗方向与业务预期一致。
执行批量清洗、抽取、合并与标准化处理,并输出质量报告。
交付结果文件或接口,并支持后续持续治理与规则迭代。
通过场景化表达提升页面商业说服力,同时让“数据清洗服务”“企业数据治理”“票据识别与清洗”等关键词自然落在页面主体中。
清洗商品库、订单库、会员库与活动数据,统一编码和标签体系,支撑精准营销与经营分析。
规范客户主体信息、票据资料、授信材料与流水字段,降低核验成本并增强风控质量。
对工商、税务、项目申报、档案资料等多源数据做治理,提升公共数据可用性与合规性。
清洗物料、供应商、仓储与采购数据,统一主数据标准,减少供应链协同错误。
病历、表单、检测与档案资料结构化清洗,辅助医疗数据归档、研究和流程管理。
对合同、卷宗、证据材料、扫描件做字段抽取与清洗,便于检索、归档与合规留痕。

借助AI工具,帮自己降本增效。面对海量数据和复杂场景,我们没必要投入大量人力写代码,选择沙淘金数据这类专业的AI数据清洗工具,通过低代码配置就能完成复杂的清洗逻辑,既能提升效率,又能保证准确率,让我们把时间花在更核心的工作上。

不良资产处置业务环节繁琐、涉及资料繁杂,借款合同、抵押物权属证明、催收记录、法院裁判文书、资产清单、银行流水、尽调报告等核心资料,均以PDF格式存储归档,且普遍存在年代久远、扫描件模糊、印章覆盖、版式不统一、信息分散的问题,传统人工处理模式严重制约处置进度,影响资产回款效率。武汉沙淘金聚焦不良资产处置场景,推出的非结构化数据治理服务,可彻底破解这一行业痛点。

武汉沙淘金深耕不良资产处置行业,精准洞察行业数据管理痛点,依托专业的技术能力与丰富的行业经验,推出不良资产数据深度整合服务,以数据规范化、管理集中化、应用便捷化,助力从业者破解数据管理难题,推动不良资产处置流程优化、效率提升,赋能行业高质量发展。

在数据驱动的时代,“拥有数据”不再是优势,“用好数据”才是企业的核心竞争力。数据清洗正是将“杂乱数据”转化为“可利用资产”的步——它不仅能帮企业降低运营成本、提升决策效率,更能为后续的数据分析、AI应用筑牢基础。

某制造企业数据团队曾花3天删除了20万条“空值数据”,结果月度报表依然出错——原来真正的问题是“同一客户的重复数据”“格式混乱的订单日期”没解决。很多企业以为数据清洗就是“删垃圾”,但实际上,无效数据只是表层问题,没抓住核心标准的清洗,只会让企业白耗人力,还拖垮决策效率。
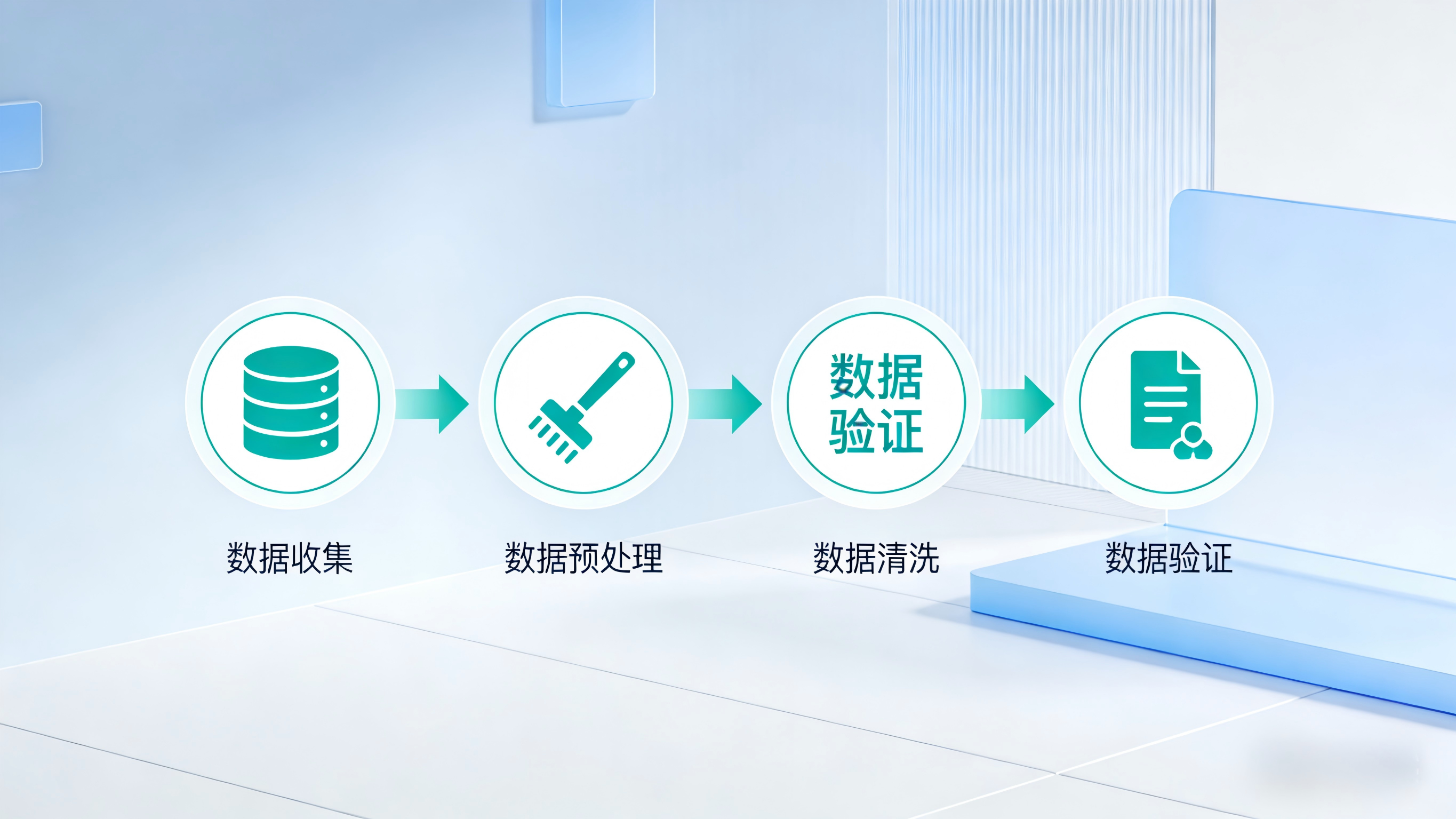
你的团队是否还在为每周核对不上的报表数据而集体加班?你的数据工程师是否仍被淹没在写不完的SQL清洗脚本里?行业数据显示,超过60%的企业数据清洗工作仍重度依赖手工,这不仅消耗着最宝贵的人力资源,更让数据响应业务的速度步履维艰。从耗时费力的“人肉”清洗,到构建一套标准化的自动化流水线,这已成为企业能否真正让数据驱动决策的关键分水岭。
数据清洗从来不是一次性工程,而是伴随模型整个生命周期的持续过程。最先进的算法也无法从被污染的数据中提炼出真知灼见。这就像最优秀的厨师无法用变质的食材做出美味佳肴。
你是否曾因报表数字对不上而焦头烂额?是否在决策时发现数据自相矛盾,最终只能凭感觉“拍板”?在数据驱动的今天,低质量的数据就像地基不稳的高楼,外表光鲜,实则危机四伏。行业研究显示,企业数据中平均高达30%存在各类错误,这不仅让分析结论失真,更可能让百万营销投入打水漂,或让关键决策南辕北辙。今天,我们就来系统拆解那些潜伏在数据中的“隐形杀手”,并告诉你如何精准识别与高效修复。

你的数据清洗流程,是否经得起凌晨三点的考验?在这个数据驱动一切的时代,最好的防御不仅是加固边界,更是确保内部每一个处理数据的环节都值得信赖。
你是否曾因报表数字对不上而焦头烂额?是否在决策时发现数据自相矛盾,最终只能凭感觉“拍板”?在数据驱动的今天,低质量的数据就像地基不稳的高楼,外表光鲜,实则危机四伏。行业研究显示,企业数据中平均高达30%存在各类错误,这不仅让分析结论失真,更可能让百万营销投入打水漂,或让关键决策南辕北辙。今天,我们就来系统拆解那些潜伏在数据中的“隐形杀手”,并告诉你如何精准识别与高效修复。
FAQ 区块能增强页面停留、补充长尾关键词覆盖,也有助于搜索引擎理解服务边界和客户关注点。
通常包含重复数据清理、空值与异常值修复、字段规范化、编码统一、格式转换、资料结构化抽取以及结果校验与交付报告。
可以。通常先通过 OCR 或结构化识别把内容抽取出来,再结合业务规则进行清洗、归一化和字段映射。
通过样本验证、规则迭代、人工抽检、结果对比和异常复核来保障准确率,并根据验收标准输出质量说明。
支持。可以按行业、字段字典、系统接口规范、企业口径以及审计要求定制清洗规则与交付结构。
