电商与零售
清洗商品库、订单库、会员库与活动数据,统一编码和标签体系,支撑精准营销与经营分析。
面向政企、金融、电商、制造、医疗等场景,提供重复数据去重、字段规范化、缺失修复、异常值治理等全链路服务,帮助企业大幅提升数据可用性与分析效率。
营销型站点不仅要展示服务,还要清晰表达客户痛点、解决路径与商业价值。这个页面围绕“转化 + SEO”设计,用结构化信息帮助搜索引擎理解,也让客户快速判断是否适合合作。
客户库、订单库、供应商库重复记录过多,导致销售触达冲突、分析失真与存储浪费。
手机号、地址、统一社会信用代码等关键字段缺失或异常,影响后续业务联动与风控判断。
同一字段存在多种录入方式,难以做聚合、对比、统计与自动化流转。
不准确的数据会带来决策偏差,也可能在审计、风控与客户服务环节形成隐患。
我们并非只做简单格式修正,而是结合业务规则、行业标准与目标系统要求,对数据进行清洗、校验、归一、映射与结构化交付。
去重、去空格、符号修正、乱码处理、非法字符过滤、日期与编码规范化。
基于企业业务规则校验字段逻辑、主外键关系、状态流转与必填一致性。
对票据、证照、合同、文本、图片资料做结构化抽取并对接清洗流程。
支持 Excel、CSV、数据库表、API 字段映射、标签体系与治理报告输出。
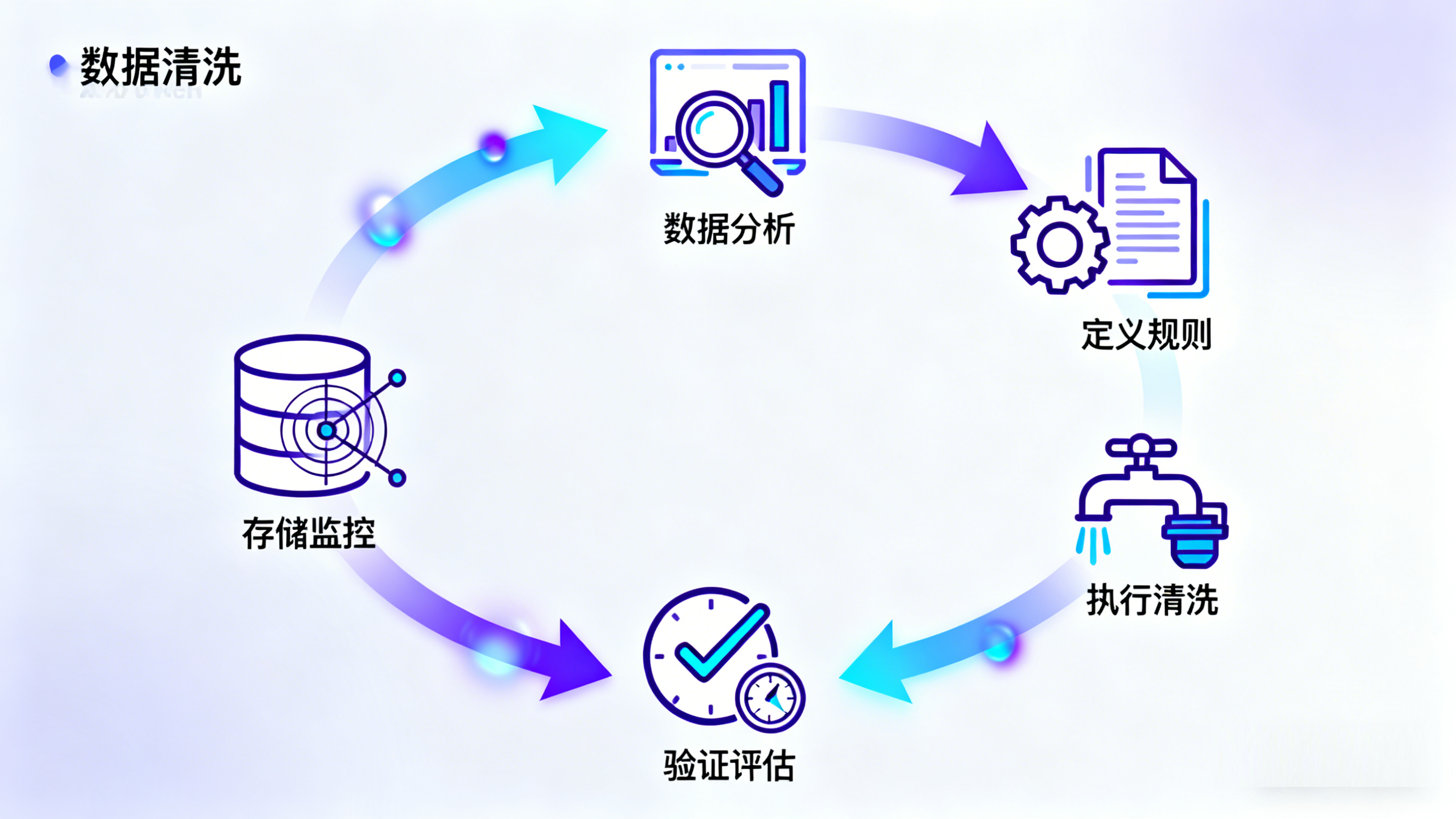
明确数据来源、字段结构、业务目标、质量问题与验收标准。
制定清洗规则、映射规则、去重逻辑和异常值处理策略。
先用样本数据验证规则效果,确保清洗方向与业务预期一致。
执行批量清洗、抽取、合并与标准化处理,并输出质量报告。
交付结果文件或接口,并支持后续持续治理与规则迭代。
通过场景化表达提升页面商业说服力,同时让“数据清洗服务”“企业数据治理”“票据识别与清洗”等关键词自然落在页面主体中。
清洗商品库、订单库、会员库与活动数据,统一编码和标签体系,支撑精准营销与经营分析。
规范客户主体信息、票据资料、授信材料与流水字段,降低核验成本并增强风控质量。
对工商、税务、项目申报、档案资料等多源数据做治理,提升公共数据可用性与合规性。
清洗物料、供应商、仓储与采购数据,统一主数据标准,减少供应链协同错误。
病历、表单、检测与档案资料结构化清洗,辅助医疗数据归档、研究和流程管理。
对合同、卷宗、证据材料、扫描件做字段抽取与清洗,便于检索、归档与合规留痕。

数据清洗的本质,是让数据从“原始素材”转化为“可用资产”的过程。它存在三重递进的境界,绝大多数企业只停留在第一重。
筛斗数据平台的核心优势,在于将人工智能技术与文件解析管理深度融合,全面突破了传统处理模式的束缚。

在数字化浪潮下,数据已成为企业决策的 “核心资产”。但现实中,企业收集的数据往往存在 “脏数据” 问题:客户信息重复录入、订单日期格式混乱、数值字段存在异常值、空白数据遗漏填充…… 这些看似微小的瑕疵,却可能导致市场分析失真、决策判断失误、业务流程受阻。

硅谷的投资人还在为下一个万亿参数模型兴奋不已,北京的AI实验室里却在上演着另一番景象。一位资深数据科学家指着屏幕上跳动的训练曲线,对团队说:“我们不是在教AI学习,是在教它模仿我们的混乱。”他们的模型准确率卡在82%已经三周了——不是因为算法不够精妙,而是训练数据里那些自相矛盾的标签,让AI陷入了困惑。

我们喂养AI的每一口数据,都可能暗藏毒素。当ChatGPT对答如流、Sora生成精美视频时,很少有人知道,这些能力建立在数百万小时的数据清洗劳动之上——而这个过程,充满不为人知的算法偏见和政治权衡。
在数据爆炸的时代,数据已成为企业决策、科学研究和日常运营的重要资产。然而,原始数据往往充斥着错误、缺失、不一致和噪声,这些“脏数据”如果直接用于分析和建模,会导致结果偏差,影响决策的有效性。因此,数据清洗作为数据处理的第一步,显得尤为重要。本文将深入探讨数据清洗的内容和方法,帮助读者全面理解这一关键过程。

11月22日下午,中国仲裁法学研究会会员、全国中等城市仲裁机构发展研究专委会副主任王祥生;湖北省数字化转型专家咨询委员会委员、省政府采购评审专家苏平;全国中等城市网络仲裁开拓者、十堰仲裁委副秘书长刘汉平、湖北卡莱律师事务所贺润律师等一行领导莅临湖北十团网络科技股份有限公司武汉分公司、武汉沙淘金信息技术有限公司考察调研,公司董事长杨辉亲切接待各领导并展开调研。

当奔驰、宝马、长安等车企在中国获得L3级自动驾驶测试牌照时,鲜少有人意识到,这些牌照背后是一场旷日持久的“数据洗白”战争。每一辆测试车每天产生2TB数据,而真正能用于模型训练的不足0.3%。


某零售企业的营销总监最近很困惑:他们投入百万预算的精准营销活动,响应率却只有可怜巴巴的15%。直到技术人员打开CRM系统,才发现了触目惊心的真相——同一个客户在系统里被重复记录了8次,1200万条客户数据中竟有18万条重复信息。更糟糕的是,25万条关键联系字段是空白的。这意味着,每次营销推送都是在向“不存在”的客户喊话。这不是个别现象。调研数据显示,80%的企业在数字化转型中,都卡在了同一个环节:数据质量。
FAQ 区块能增强页面停留、补充长尾关键词覆盖,也有助于搜索引擎理解服务边界和客户关注点。
通常包含重复数据清理、空值与异常值修复、字段规范化、编码统一、格式转换、资料结构化抽取以及结果校验与交付报告。
可以。通常先通过 OCR 或结构化识别把内容抽取出来,再结合业务规则进行清洗、归一化和字段映射。
通过样本验证、规则迭代、人工抽检、结果对比和异常复核来保障准确率,并根据验收标准输出质量说明。
支持。可以按行业、字段字典、系统接口规范、企业口径以及审计要求定制清洗规则与交付结构。
