数据清洗


你的数据库,正在被AI悄悄“下毒”
数据清洗从来不是一次性工程,而是持续的过程。面对AI生成内容带来的新挑战,每个依赖数据决策的企业都需要重新审视自己的数据管理策略。或许可以从一个简单的自查开始:随机抽检近期新增的用户内容,看看其中有多少可能来自AI;检查你的推荐系统是否曾被虚假数据影响;评估你的分析报告在多大程度上建立在真实信息之上。

L3自动驾驶获批背后的“数据洗白”战争
当奔驰、宝马、长安等车企在中国获得L3级自动驾驶测试牌照时,鲜少有人意识到,这些牌照背后是一场旷日持久的“数据洗白”战争。每一辆测试车每天产生2TB数据,而真正能用于模型训练的不足0.3%。

AI的“毒饲料”:揭秘大模型训练中不为人知的数据清洗
我们喂养AI的每一口数据,都可能暗藏毒素。当ChatGPT对答如流、Sora生成精美视频时,很少有人知道,这些能力建立在数百万小时的数据清洗劳动之上——而这个过程,充满不为人知的算法偏见和政治权衡。

数据清洗:企业数字化转型的“基石工程”
在数字化浪潮下,数据已成为企业决策的 “核心资产”。但现实中,企业收集的数据往往存在 “脏数据” 问题:客户信息重复录入、订单日期格式混乱、数值字段存在异常值、空白数据遗漏填充…… 这些看似微小的瑕疵,却可能导致市场分析失真、决策判断失误、业务流程受阻。

AI撞上了看不见的天花板:当算力狂奔,数据却在原地踏步
硅谷的投资人还在为下一个万亿参数模型兴奋不已,北京的AI实验室里却在上演着另一番景象。一位资深数据科学家指着屏幕上跳动的训练曲线,对团队说:“我们不是在教AI学习,是在教它模仿我们的混乱。”他们的模型准确率卡在82%已经三周了——不是因为算法不够精妙,而是训练数据里那些自相矛盾的标签,让AI陷入了困惑。
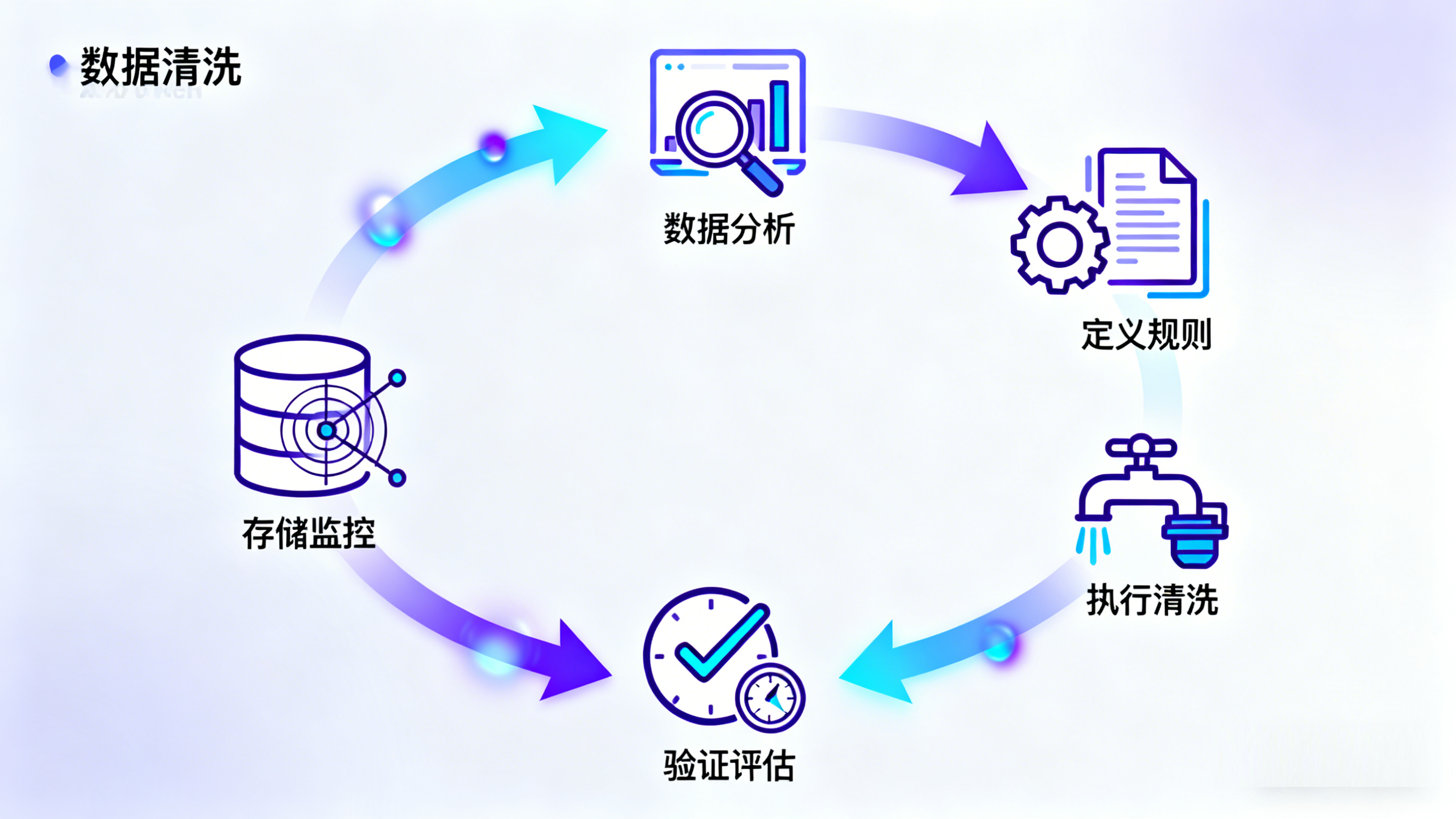
数据清洗:从“脏数据”到“干净数据”的蜕变之旅
在数据爆炸的时代,数据已成为企业决策、科学研究和日常运营的重要资产。然而,原始数据往往充斥着错误、缺失、不一致和噪声,这些“脏数据”如果直接用于分析和建模,会导致结果偏差,影响决策的有效性。因此,数据清洗作为数据处理的第一步,显得尤为重要。本文将深入探讨数据清洗的内容和方法,帮助读者全面理解这一关键过程。

大数据不只是 “海量数据”,更是驱动时代的创新引擎
大数据的价值,早已超越技术本身,深度融入各行各业的核心场景,成为产业升级的 “隐形引擎”。

当我们谈论数据清洗,我们到底在谈论什么?
数据清洗的本质,是让数据从“原始素材”转化为“可用资产”的过程。它存在三重递进的境界,绝大多数企业只停留在第一重。

数据清洗:仲裁行业数字化转型的“证据基石”与“效率引擎”
仲裁作为多元化纠纷解决机制的核心组成,其业务全流程高度依赖数据支撑 —— 从当事人信息、证据材料、案件审理记录到裁决文书,每一环都产生海量数据。但传统仲裁数据管理中,普遍存在三大核心痛点,让数据清洗成为数字化转型的 “必选项”:
