电商与零售
清洗商品库、订单库、会员库与活动数据,统一编码和标签体系,支撑精准营销与经营分析。
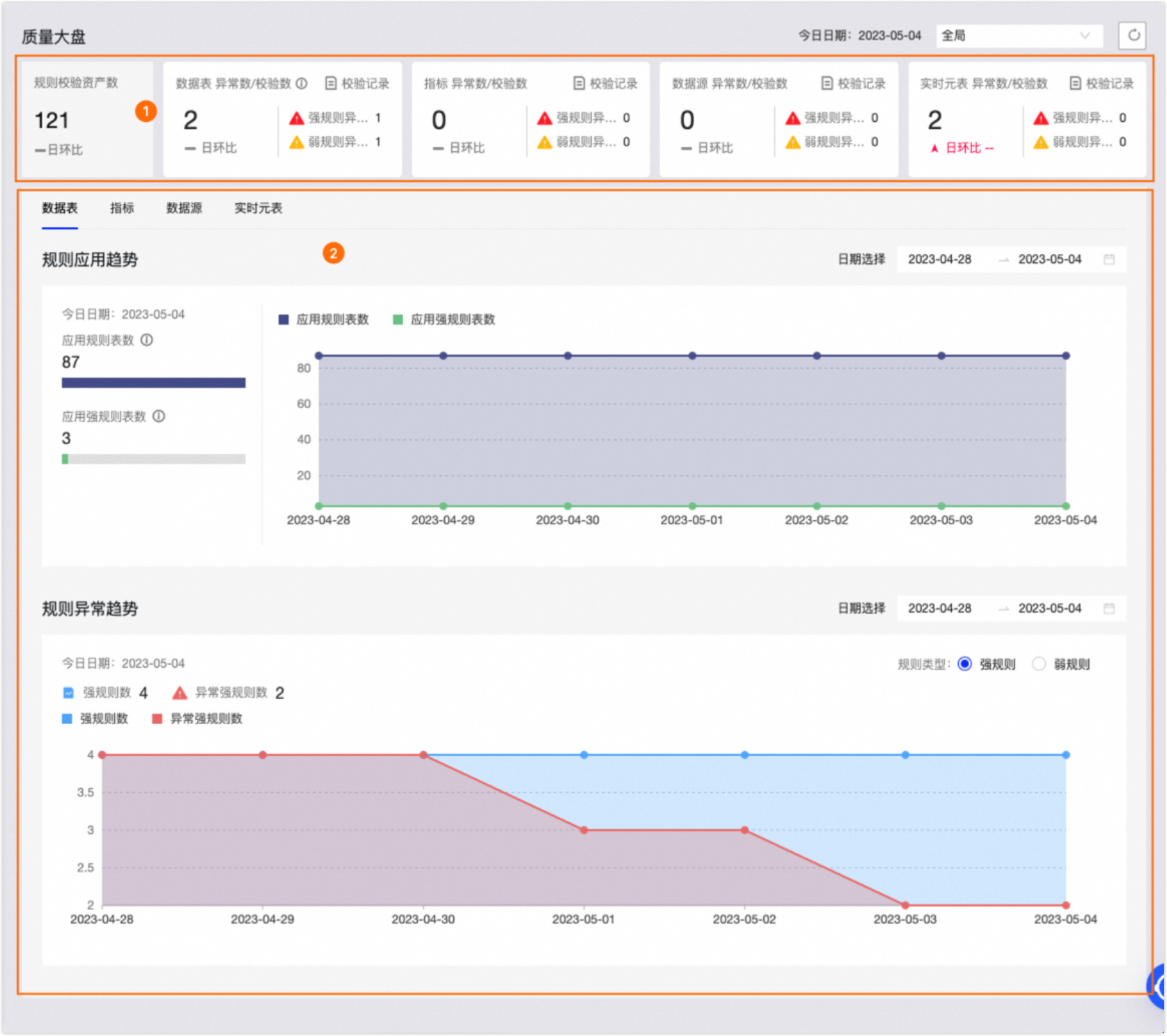
面向政企、金融、电商、制造、医疗等场景,提供重复数据去重、字段规范化、缺失修复、异常值治理等全链路服务,帮助企业大幅提升数据可用性与分析效率。
营销型站点不仅要展示服务,还要清晰表达客户痛点、解决路径与商业价值。这个页面围绕“转化 + SEO”设计,用结构化信息帮助搜索引擎理解,也让客户快速判断是否适合合作。
客户库、订单库、供应商库重复记录过多,导致销售触达冲突、分析失真与存储浪费。
手机号、地址、统一社会信用代码等关键字段缺失或异常,影响后续业务联动与风控判断。
同一字段存在多种录入方式,难以做聚合、对比、统计与自动化流转。
不准确的数据会带来决策偏差,也可能在审计、风控与客户服务环节形成隐患。
我们并非只做简单格式修正,而是结合业务规则、行业标准与目标系统要求,对数据进行清洗、校验、归一、映射与结构化交付。
去重、去空格、符号修正、乱码处理、非法字符过滤、日期与编码规范化。
基于企业业务规则校验字段逻辑、主外键关系、状态流转与必填一致性。
对票据、证照、合同、文本、图片资料做结构化抽取并对接清洗流程。
支持 Excel、CSV、数据库表、API 字段映射、标签体系与治理报告输出。
明确数据来源、字段结构、业务目标、质量问题与验收标准。
制定清洗规则、映射规则、去重逻辑和异常值处理策略。
先用样本数据验证规则效果,确保清洗方向与业务预期一致。
执行批量清洗、抽取、合并与标准化处理,并输出质量报告。
交付结果文件或接口,并支持后续持续治理与规则迭代。
通过场景化表达提升页面商业说服力,同时让“数据清洗服务”“企业数据治理”“票据识别与清洗”等关键词自然落在页面主体中。
清洗商品库、订单库、会员库与活动数据,统一编码和标签体系,支撑精准营销与经营分析。
规范客户主体信息、票据资料、授信材料与流水字段,降低核验成本并增强风控质量。
对工商、税务、项目申报、档案资料等多源数据做治理,提升公共数据可用性与合规性。
清洗物料、供应商、仓储与采购数据,统一主数据标准,减少供应链协同错误。
病历、表单、检测与档案资料结构化清洗,辅助医疗数据归档、研究和流程管理。
对合同、卷宗、证据材料、扫描件做字段抽取与清洗,便于检索、归档与合规留痕。
在数字化浪潮中,企业每天沉淀海量数据,却常因字段错乱、格式混乱、信息缺失而难以支撑精准决策。是不是每次开会,面对一堆杂乱报表都无从下手?本文将以6大核心步骤,带你系统化梳理数据清洗全流程,让“脏数据”焕发生机。

深夜11点,办公室里只剩下键盘敲击声。刚转正的数据分析师小李接到“紧急任务”——清洗一批VIP客户数据,第二天一早交付。他熟练地删除重复项、填充缺失值,按下“保存”时,还得意于自己的高效。

在这个信息过载的世界里,清洗数据的能力正在成为一种新的生存智慧。无论对商家还是消费者,能够从海量信息中识别真实、过滤噪音的人,才是这个时代真正的聪明消费者。

某零售企业的营销总监最近很困惑:他们投入百万预算的精准营销活动,响应率却只有可怜巴巴的15%。直到技术人员打开CRM系统,才发现了触目惊心的真相——同一个客户在系统里被重复记录了8次,1200万条客户数据中竟有18万条重复信息。更糟糕的是,25万条关键联系字段是空白的。这意味着,每次营销推送都是在向“不存在”的客户喊话。这不是个别现象。调研数据显示,80%的企业在数字化转型中,都卡在了同一个环节:数据质量。

每次当你刷卡支付时,背后都有一整套数据清洗系统在默默工作。它过滤掉欺诈的尝试,保留你真实的交易,就像筛子留下米粒,筛掉砂石。

最好的系统不是永不犯错,而是懂得何时交还人类判断。有些判断关乎的不仅是数据准确,更是人间冷暖。在算法时代,真正的智能不仅在于识别模式,更在于理解世界。而这一切,始于认真对待每一条信息——在清洗中辨别真伪,在分析中保持温度。

普及的当下,车辆每一秒都在产生海量运行数据——电池电压、电机转速、充电状态、车速变化等,这些数据是故障预警、电池寿命管理、安全运营的核心依据。然而,原始车辆数据如同混杂着沙砾的矿石,充斥着各类“杂质”:传感器异常读数、充电中断导致的缺失值、不同设备采集的格式差异等。

最近新能源车行业有个公开的秘密:各家宣传的续航里程很漂亮,但车主实际体验往往打折扣。问题可能不全是电池技术——有工程师透露,车载传感器收集的电池数据中,平均有20%是错误值。

做电商的朋友都有过这种崩溃时刻:月底汇总销售数据,Excel表格里塞满了乱码、重复记录、空白值——明明后台显示有1000单成交,整理完却只剩800单;想分析爆款的用户画像,却发现一半收货地址是“无”,手机号格式乱七八糟。其实问题不是数据没用,而是你没做好“数据清洗”这一步。

数据清洗从来不是一次性工程,而是持续的过程。面对AI生成内容带来的新挑战,每个依赖数据决策的企业都需要重新审视自己的数据管理策略。或许可以从一个简单的自查开始:随机抽检近期新增的用户内容,看看其中有多少可能来自AI;检查你的推荐系统是否曾被虚假数据影响;评估你的分析报告在多大程度上建立在真实信息之上。
FAQ 区块能增强页面停留、补充长尾关键词覆盖,也有助于搜索引擎理解服务边界和客户关注点。
通常包含重复数据清理、空值与异常值修复、字段规范化、编码统一、格式转换、资料结构化抽取以及结果校验与交付报告。
可以。通常先通过 OCR 或结构化识别把内容抽取出来,再结合业务规则进行清洗、归一化和字段映射。
通过样本验证、规则迭代、人工抽检、结果对比和异常复核来保障准确率,并根据验收标准输出质量说明。
支持。可以按行业、字段字典、系统接口规范、企业口径以及审计要求定制清洗规则与交付结构。
